
QwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management
![]()
![]()
Weizhou Shen*, Ziyi Yang*, Chenliang Li*, Zhiyuan Lu, Miao Peng, Huashan Sun, Yingcheng Shi, Shengyi Liao, Shaopeng Lai, Bo Zhang, Dayiheng Liu, Fei Huang, Jingren Zhou, Ming Yan†
Tongyi Lab, Alibaba Group
📚 Introduction
Long-context reasoning is a critical capability for modern Large Language Models (LLMs), yet a significant gap exists in the post-training stage. The field lacks a mature, end-to-end system that provides: (1) a scalable pipeline for synthesizing challenging long-context reasoning data, (2) reinforcement learning (RL) methods tailored to the nuances of long-context reasoning, and (3) agent architectures designed to operate on information streams that exceed the model's context capacity.
In this work, we introduce QwenLong-L1.5, a long-context reasoning model built upon Qwen3-30B-A3B-Thinking, augmented with memory mechanisms to process tasks far beyond its physical context window. Our core contribution is a full post-training recipe that unifies data synthesis, training methodologies, and agent architectures.
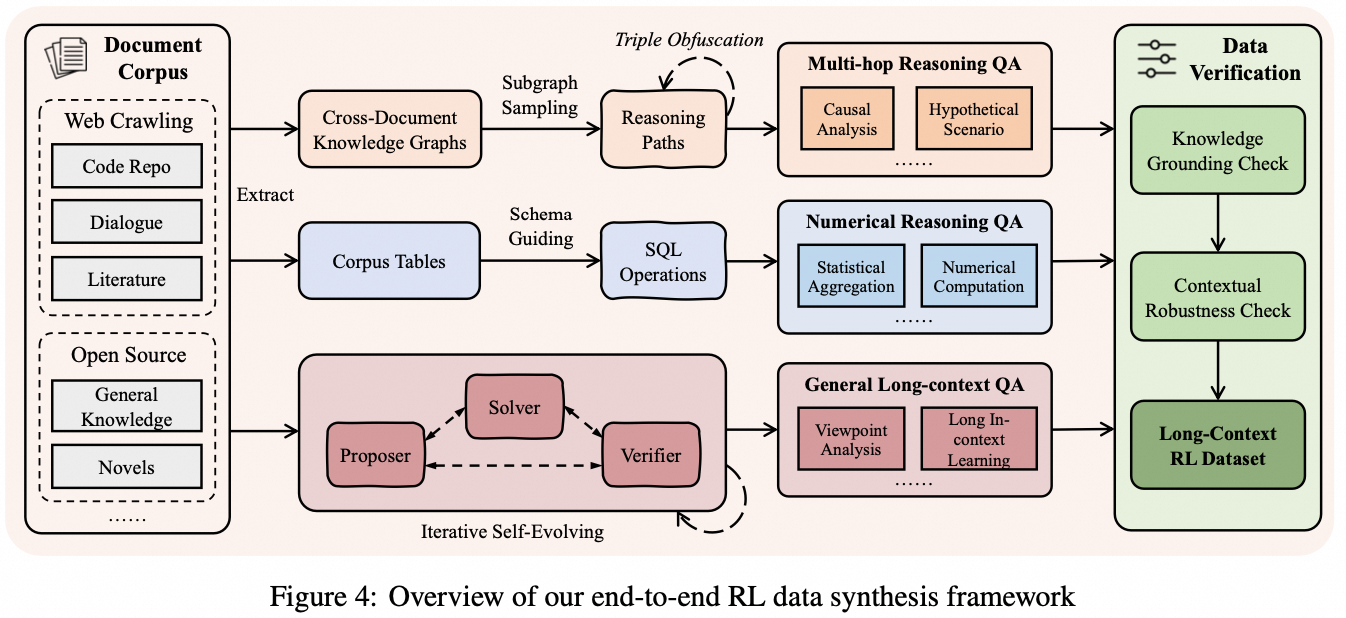
First, to address the scarcity of high-quality data, we developed a novel synthesis pipeline that moves beyond simple "needle-in-a-haystack" tasks. Instead, it focuses on creating challenges that require multi-hop grounding and reasoning over globally distributed evidence. This is achieved by deconstructing source documents into atomic facts and programmatically composing complex, verifiable questions from this structured information.
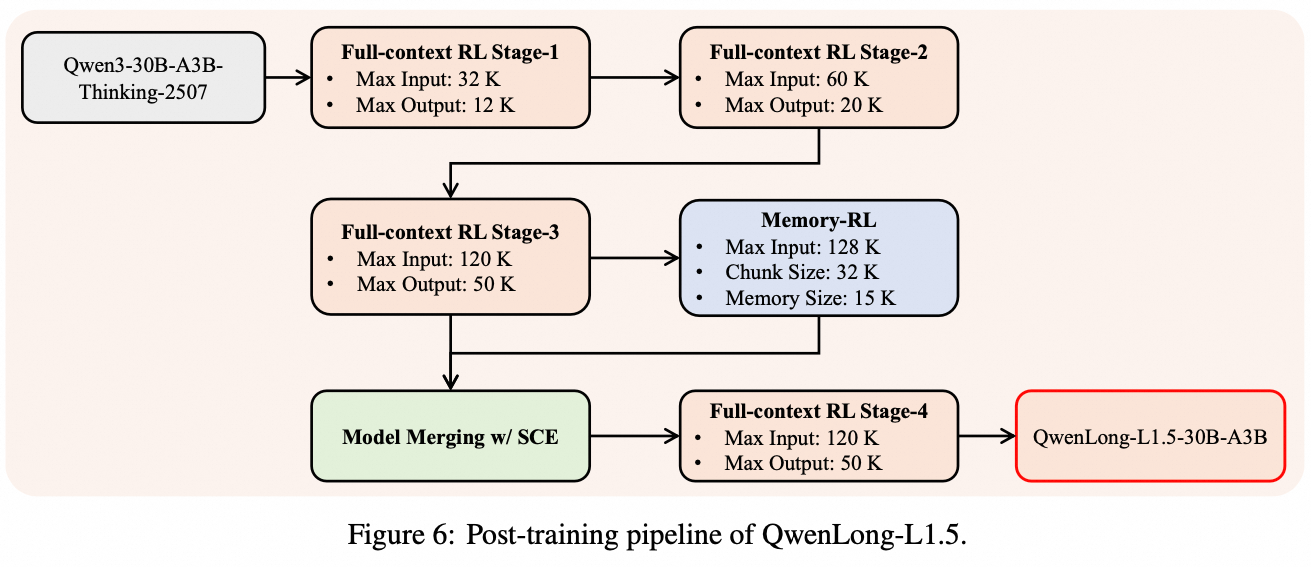
Second, we introduce several RL strategies to tackle the instability of long-context training. This includes task-balanced sampling to stabilize mini-batch distributions and our novel Adaptive Entropy-Controlled Policy Optimization (AEPO) algorithm, which employs an entropy-based mechanism to actively control gradients and sustain training on sequences of progressively increasing length.
Third, to handle tasks exceeding the model's physical window, we introduce a memory management framework. Through a multi-stage fusion RL paradigm, we synergistically combine the model's single-pass reasoning (within its 256K window) with an iterative memory updating mechanism to extend its operational range.
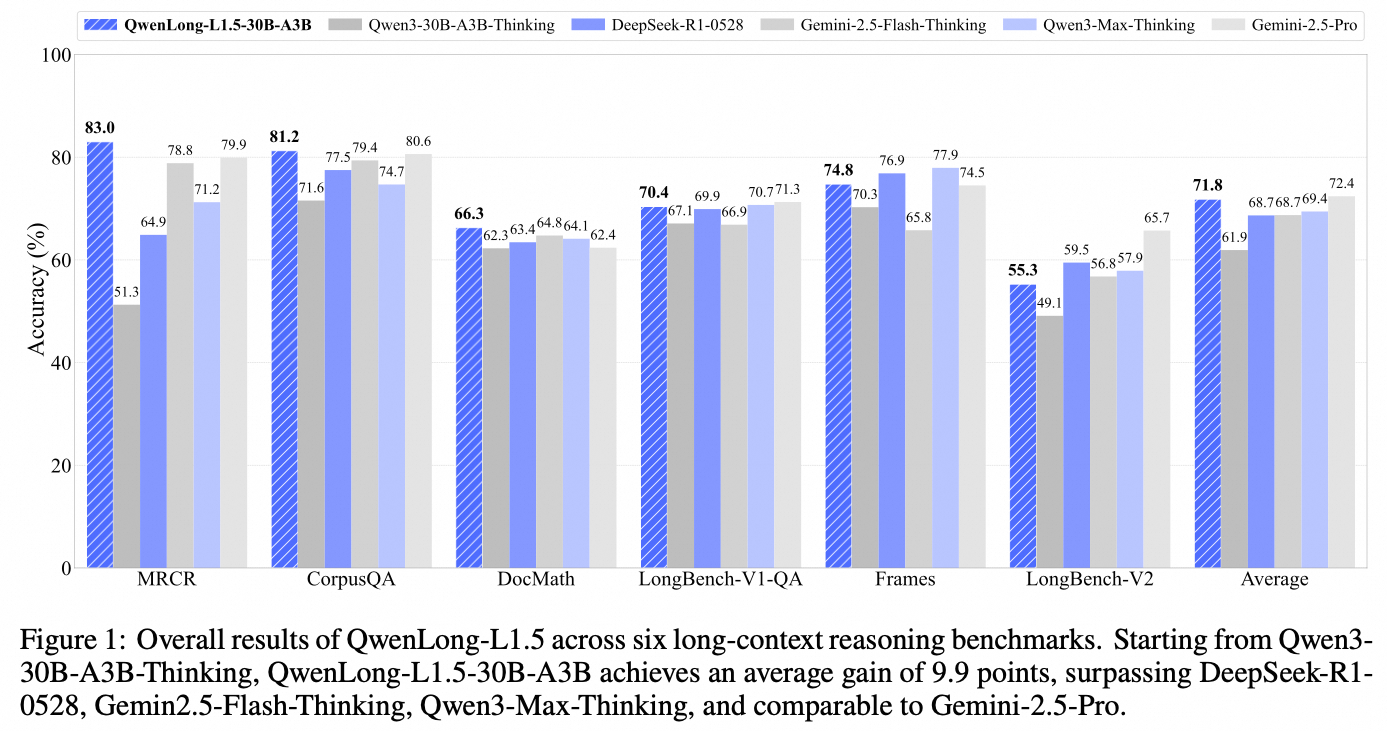
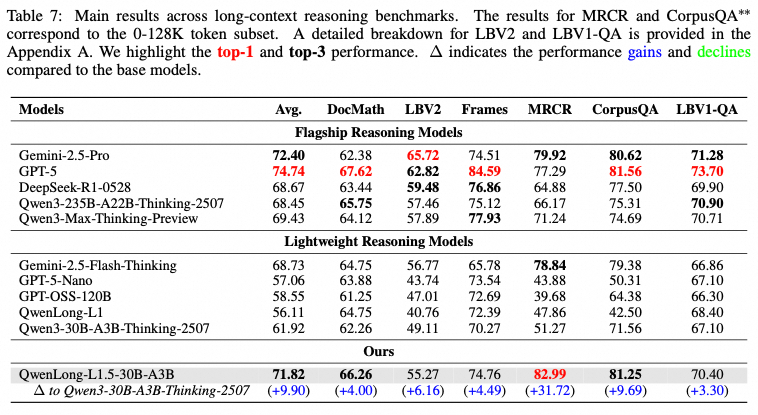
Our comprehensive evaluation on leading long-context benchmarks shows that QwenLong-L1.5 surpasses its Qwen3-30B-A3B-Thinking baseline by an average of 9.9 points, achieving performance comparable to top-tier models like GPT-5 and Gemini-2.5-Pro. Crucially, these enhancements also translate to significant gains in general domains like mathematics, tool-use, and long-dialogue scenarios, demonstrating that strong long-context ability provides a foundational boost to a model's overall reasoning capabilities.
🛠️ Requirements
# Create the conda environment
conda create -n qwenlongl1_5 python==3.10
conda activate qwenlongl1_5
# Install requirements
pip3 install -r requirements.txt
# Install verl, we use the 0.4 version of verl
git clone --branch v0.4 https://github.com/volcengine/verl.git
cd verl
pip3 install -e .
🚀 Quick Start
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Tongyi-Zhiwen/QwenLong-L1.5-30B-A3B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
template = """Please read the following text and answer the question below.
<text>
$DOC$
</text>
$Q$
Format your response as follows: "Therefore, the answer is (insert answer here)"."""
context = "<YOUR_CONTEXT_HERE>"
question = "<YOUR_QUESTION_HERE>"
prompt = template.replace('$DOC$', context.strip()).replace('$Q$', question.strip())
messages = [
# {"role": "system", "content": "You are QwenLong-L1, created by Alibaba Tongyi Lab. You are a helpful assistant."}, # Use system prompt to define identity when needed.
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=50000,
temperature=0.7,
top_p=0.95
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151649 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
📝 Citation
If you find this work is relevant with your research or applications, please feel free to cite our work!
@article{shen2025qwenlongl15,
title={QwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management},
author={Weizhou Shen and Ziyi Yang and Chenliang Li and Zhiyuan Lu and Miao Peng and Huashan Sun and Yingcheng Shi and Shengyi Liao and Shaopeng Lai and Bo Zhang and Dayiheng Liu and Fei Huang and Jingren Zhou and Ming Yan},
journal={arXiv preprint arXiv:2512.12967},
year={2025}
}
- Downloads last month
- 310